
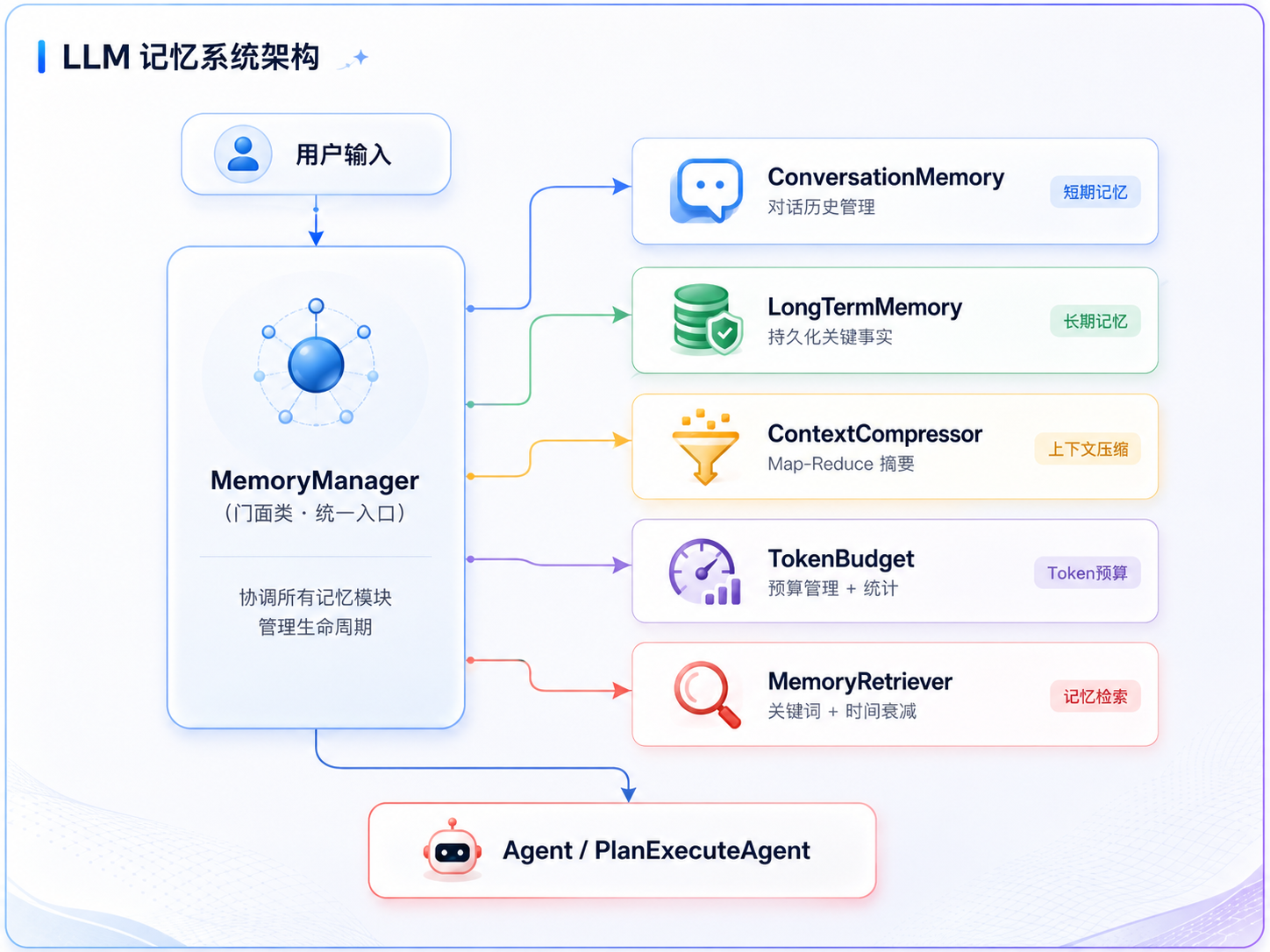
Memory
Memory的整体设计
记忆的基本单元
一个智能体的记忆,要有什么时间产生的(方便做时间衰减),什么类型的,占多少token,有没有附加信息。
public class MemoryEntry {
private final String id;
private final String content;
private final MemortType type;
private final Instant timestamp;
private final Map<String,String> metadata;
private final int tokencount;
public enum MemryType {
CONVERSATION;
FACT;
SUMMARY;
TOOL_RESULT;
}
}CONVERSATION 是对话消息,FACT 是用户偏好、项目信息这类关键事实,SUMMARY 是压缩后的摘要,TOOL_RESULT 是工具执行结果。
TOOL_RESULT 之所以单独分出来,是因为工具返回的内容通常特别长(比如读一个文件能返回几百行),但检索的时候又需要知道“之前执行过什么命令”。标记出来之后,压缩时可以对工具结果更激进地砍,对话内容则多保留一些语义。
token估算
public static int estimateTokens(String text) {
if (text==null ||text.isEmpty()) return 0;
long chineseChars = text.chars()
.filter(c -> c > 0x4E00 && c < 0x9FFF).count;
long otherChars = text.length() - chineseChars;
return (int) Math.ceil(chineseChars / 1.5 + otherChars / 4.0);
}短期记忆
短期记忆干两件事:存消息和自动淘汰。
token 预算是有限的,聊多了总会撑满。这时候最简单的策略就是淘汰最旧的消息——跟操作系统的页面置换一个道理,内存不够了就把最久没用的页面换出去。对话是顺序的,最旧的消息通常最不重要,FIFO 就够了。
public class ConversationMemory implements Memory {
private final int LinkedHashMap<String,MemoryEntry> entries;
private final int maxTokens;
private final AtomicInteger currentTokens;
private final List<MemoryEntry> compressedSummaries;
@Overried
public void store(Memory Entry) {
entries.put(entry.getId(),id);
currentTokens.addAndGet(entry.getTokenCount());
while(currentTokens.get()>maxToken &&entries.size()>1) {
evictOldest();
}
}
}被淘汰的消息不会直接扔掉,而是放进 compressedSummaries 列表,等着后面压缩成摘要——信息还在,只是换了个更紧凑的形态。
getUsageRatio() 返回当前 token 使用率,超过 80% 的时候 MemoryManager 就会自动触发 ContextCompressor 来做压缩。
长期记忆
短期记忆会话关了就没了,长期记忆才是要存到磁盘上的。
public class LongTermMemory implements Memory {
private static final String STORAGE_DIR = ".agri/memory";
private static final String STORAGE_FILE = "long_term_memory.json";
public LongTermMemory() {
// 启动时从磁盘加载
loadFromDisk();
}
@Override
public void store(MemoryEntry entry) {
// 去重检查:内容完全相同则跳过
Optional<Map.Entry<String, MemoryEntry>> existing = entries.entrySet().stream()
.filter(e -> e.getValue().getContent().equals(entry.getContent()))
.findFirst();
if (existing.isPresent()) return;
entries.put(entry.getId(), entry);
tokenCounter.addAndGet(entry.getTokenCount());
saveToDisk(); // 每次存完都持久化
}
}首先是自动去重,用户连续三次说“我喜欢用 Java”,长期记忆里不会存三遍,内容相同的直接跳过。
然后是即时持久化,每次 store 都调 saveToDisk。
最后是启动时加载,Agent 启动的时候自动把之前的记忆读进来。加载时会保留原始时间戳,这一点很重要——如果时间戳被覆盖成当前时间,后面做时间衰减检索的时候,旧记忆就不会被正确衰减了。
检索这块,用向量检索。
上下文压缩
短期记忆满了,旧消息得淘汰,但关键信息不能丢。怎么办?压缩成摘要,再注入回去。
压缩策略用的是 Map-Reduce,跟处理大文档的思路一样:
Map 阶段:把旧消息分成每 5 条一组,每组独立调用 LLM 生成摘要。分组处理比一股脑扔几十条给 LLM 效果好得多,模型处理短文本的摘要质量明显更高。
Reduce 阶段:把多个分片摘要合并成最终摘要。只有一片的话直接用,不再多调一次 LLM。
public String compress(ConversationMemory memory) {
List<MemoryEntry> allEntries = memory.getAll();
// 分割:旧消息 vs 近期消息(必须拷贝,因为后面会 clear 底层集合)
int splitPoint = allEntries.size() - retainRecentRounds;
List<MemoryEntry> oldEntries = new ArrayList<>(allEntries.subList(0, splitPoint));
List<MemoryEntry> recentEntries = new ArrayList<>(allEntries.subList(splitPoint, allEntries.size()));
// Map 阶段
List<String> chunkSummaries = mapPhase(oldEntries);
// Reduce 阶段
String finalSummary = chunkSummaries.size() == 1
? chunkSummaries.get(0)
: reducePhase(chunkSummaries);
// 清空旧记忆,注入摘要,保留近期记忆
memory.clear();
memory.store(new MemoryEntry(
"summary-" + UUID.randomUUID().toString().substring(0, 8),
"[历史对话摘要] " + finalSummary,
MemoryEntry.MemoryType.SUMMARY, null,
MemoryEntry.estimateTokens(finalSummary)
));
for (MemoryEntry entry : recentEntries) memory.store(entry);
return finalSummary;
}retainRecentRounds 这个参数很关键——最近 3 轮消息不参与压缩,原样保留。刚聊的内容通常是当前任务的核心上下文,压缩可能会丢掉关键细节。
ContextCompressor 还干了一件事:事实提取。对话结束的时候,调用 extractFacts 让 LLM 从对话里提炼关键信息——用户偏好、项目配置、重要决策——自动塞进长期记忆。
public List<String> extractFacts(List<MemoryEntry> entries,
LongTermMemory longTermMemory) {
// 用 LLM 从对话中提取关键事实
String prompt = String.format(EXTRACT_FACTS_PROMPT, conversation);
GLMClient.ChatResponse response = llmClient.chat(messages, List.of());
// 解析事实,逐条存入长期记忆
for (String fact : facts) {
longTermMemory.store(new MemoryEntry(..., MemoryType.FACT, ...));
}
return facts;
}Token 预算管理
这玩意儿不是一个简单的计数器,而是一个预算分配器。
模型的上下文窗口就那么大,GLM-5.1 是 200K。但这 200K 不能全给对话历史用,系统提示词要占一块,工具定义要占一块,模型生成回复也得留出空间。
public class TokenBudget {
private final int contextWindow; // 200000
private final int reservedForSystem; // 500
private final int reservedForTools; // 800
private final int reservedForResponse; // 2000
public int getAvailableForConversation() {
return contextWindow - reservedForSystem
- reservedForTools - reservedForResponse;
// 200000 - 500 - 800 - 2000 = 196700
}
public boolean needsCompression(ConversationMemory memory) {
return memory.getTokenCount()
> getAvailableForConversation() * 0.8;
}
}对话历史超过 80% 预算就触发压缩。留 20% 余量是因为 token 估算本身就不精确(我们用的是字符数估算,不是真正的 tokenizer),卡太死容易翻车。
TokenBudget 还顺带记录了每次 LLM 调用的 token 消耗,调试的时候很好用:
public void recordUsage(int inputTokens, int outputTokens) {
totalInputTokens += inputTokens;
totalOutputTokens += outputTokens;
llmCallCount++;
}
public String getUsageReport() {
return String.format(
"Token 统计: 调用 %d 次 | 总输入: %d | 总输出: %d",
llmCallCount, totalInputTokens, totalOutputTokens);
}记忆检索
短期记忆和长期记忆都有了,但 Agent 处理新输入的时候,不能把 100 条记忆全塞给 LLM——大部分跟当前任务根本不沾边,纯属浪费 token。
MemoryRetriever 干的就是从两层记忆里把最相关的条目捞出来。
public List<MemoryEntry> retrieve(String query, int limit) {
List<ScoredEntry> scored = new ArrayList<>();
// 从短期记忆中检索
for (MemoryEntry entry : shortTermMemory.getAll()) {
double score = computeRelevanceScore(entry, query);
if (score > 0) scored.add(new ScoredEntry(entry, score, true));
}
// 从长期记忆中检索(权重 ×1.2,因为更精炼)
for (MemoryEntry entry : longTermMemory.getAll()) {
double score = computeRelevanceScore(entry, query) * 1.2;
if (score > 0) scored.add(new ScoredEntry(entry, score, false));
}
return scored.stream()
.sorted(Comparator.comparingDouble(ScoredEntry::score).reversed())
.limit(limit)
.map(ScoredEntry::entry)
.collect(Collectors.toList());
}相关度计算考虑了三个维度:关键词匹配——把查询分词后逐词匹配,命中越多分数越高;时间衰减——24 小时内从 1.0 线性衰减到 0.5,三天前的旧事权重自然就低了;来源加权——长期记忆的条目是经过提取和精炼的,信息密度更高,给 1.2 倍权重。
检索结果通过 buildContextForQuery 拼成文本,注入到 LLM 的输入里。Agent 那边改动很小,构建消息时带上记忆上下文就行。